Diary - What is efficient reinforcement learning in LLMs, part 2 (feat. Qwen-3.5 and GLM-5)
26 Feb 2026I’ve been writing a post called What is efficient reinforcement learning in LLMs, and then Qwen-3.5 and GLM-5 were released. Seeing them sparked a lot of thoughts again… lol. Anyway, once more from the perspective of efficient RL, I’m organizing the key contents of the two models and my thoughts.
Async RL
Both GLM-5 and Qwen3.5 focused on strengthening Agent performance compared to their previous versions (naturally, given the trend of the times). So Agent RL can be seen as one of the core training pipelines, and due to the nature of Agent tasks, the time spent interacting with the environment is long. You execute a tool and wait for the result, loading web pages and receiving API responses along the way.
This is purely waiting time. Not only does the most important GPU used for Training sit idle, but the GPU isn’t being used for Inference either. Therefore, unlike other Reasoning RL, etc., Agent RL must absolutely apply an Asynchronous RL pipeline.
Asynchronous RL is a method that completely separates Rollout and Training. Originally, to rigorously use on-policy RL algorithms like the PPO family (GRPO, etc.), you have to perform RL by alternating like rollout -> training -> rollout. Rollout uses the vllm engine and training uses the megatron engine, so you load and unload parameters, and inference bubbles can occur. To solve this kind of bottleneck, async RL is a method that simply separates the GPUs used for rollout and training.
Below is a figure showing Sync RL and Async RL (source: verl)

The dilemma of Off-Policy
When you do Async RL, it can’t be perfectly on-policy. This is because the policy at the moment the rollout is generated differs from the policy at the moment of training. In practice, this difference leads to training instability and performance degradation. So even when doing a bit of async, you minimize this gap by periodically synchronizing continuously.
Qwen3.5 reportedly used a technique called “Staleness gradient bounding” (since the technical paper hasn’t been published yet I don’t know exactly, but I’m roughly guessing from the published pipeline figure). GLM-5 used the IcePop algorithm. Whatever it is, the core of how both models solved the Off-policy dilemma is the same.
Samples that have drifted too far from on-policy are decisively discarded.
To look at IcePop, if the probability ratio between the training policy and the inference policy falls outside the [0.5, 2.0] range, it makes that sample’s gradient contribution 0. I think it’s a very simple but quite effective methodology.
Obsession with GPU Utilization
Both models mention load balancing among Rollout/Training/Environment-interaction. Efforts to push GPU utilization to the limit. From personal experience, RL is incredibly expensive when measured purely by sample count, but the performance improvement margin isn’t that expensive. The number of samples trained per second is less than 1/100 compared to SFT, yet in the latter half of post-training it shows a similar margin of performance improvement. Raising GPU utilization by 1% could bring the arrival of AGI forward by a year.
In particular, looking at the pipeline figure Qwen3.5 released this time, I thought it was so beautiful, while also being certain that an enormous number of LLM engineers and infra engineers were ground down to actually implement that pipeline.
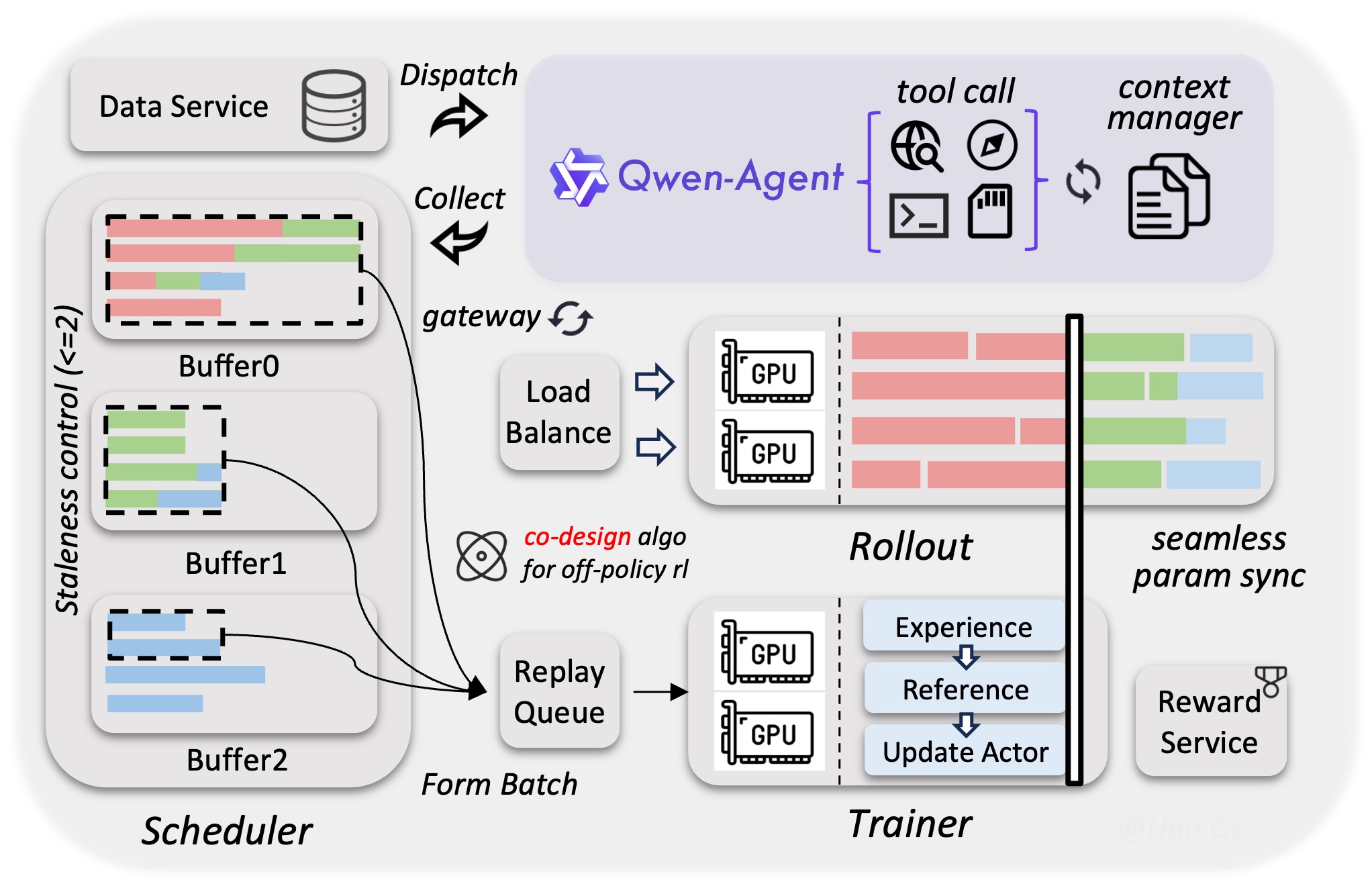
It’s written and drawn very simply, but infrastructure hardware slows down sometimes and breaks down sometimes. Also, there are communication bottlenecks when matching param sync between Training and Inference, and depending on the timing, GPU bubbles arise. Bottlenecks also occur during token redistribution after the MoE router. These points have to be considered from many angles. The Async RL framework looks simple, but there’s truly an enormous convergence of software capability behind it. I find it impressive.
Practical and powerful techniques
Actually, looking at the papers and blogs, beyond the Async RL pipeline, some very practical and powerful techniques stand out.
Qwen3.5’s dynamic precision management: It trains in FP8, and when a sensitive layer is detected, it automatically bumps it up to BF16. It catches both stability and efficiency through runtime monitoring. (Oh… this is possible during training? Not stopping and switching?)
GLM-5’s Error Masking: In multi-turn data, it doesn’t discard the parts where errors occurred. Instead, it applies a loss mask so that the error itself isn’t learned, but the behavior of correcting the error is learned. It’s applied at the SFT stage, and the idea is good. For SFT, since raising quality unconditionally is what matters, removing data with errors is the conventional wisdom. But GLM-5 says that through error-masking, it improved multi-turn performance so that even if the model gives a wrong answer, it can break out of it again in the next turn.
Inference speed improvement: In the end, the bottleneck occurs in rollout. They reportedly maximized Inference speed through speculative decoding using MTP (Multi-Token Prediction), DP-aware KV-cache, and so on. In the end, even the engineers who were in charge of API Inference latched onto the training side to make everything work well within the Async RL pipeline.
Organizing thoughts that come up late at night
Multimodal RL
The content that 2026 LLM technical papers will focus on will, I declare, be multi-modal RL. Environment interaction for image generation and audio input/output will be far more expensive than text. The time it takes to generate a single image, the time it takes to process audio. Fundamentally, it requires more time than text tokenization. Capabilities will be concentrated on reducing this bottleneck. Also, extending modality has to go through several training stages, so continued research is needed on whether the performance of multiple modalities can be raised together through expensive and unstable RL. (In fact, Qwen3.5 is an image-text-to-text model, so this part has already been considered to a certain degree.)
Still, thanks for releasing it
I’m so grateful that they release even just this much about how they trained it. I have no idea what on earth Anthropic, Google, and OpenAI are doing and how. They’re probably doing a similar process about 3 months ahead. They might be running the Async RL I mentioned above, automated with Claude Opus 4.6.
Is this about the limit for text?
Honestly, I read a technical report for the first time in a while, and the saturation is visible. The gap between models on text-based benchmarks honestly seems minimal, and the benchmarks also feel a bit forced. Also, as a user, the performance difference I actually feel isn’t large. To be honest, if you covered up all the names of the recently released models, attached them to the same opencode, and asked me to tell them apart, I don’t think I could. Maybe the problems I’m solving aren’t that hard, but I don’t think I’d have any complaints even if I suddenly switched models.
Nevertheless
But there are still many problems in the world that can’t be solved in one fell swoop by today’s SOTA models. Especially things that are hard to express in words. Humans have learned a great deal and built it into knowledge and ability, but that remains intrinsic within the person. Values, personality, cooperation, metacognition, long-term memory, the fading of memory, association. We mobilize these to solve the various problems in front of us. Still mobilizing methods that can’t be explicitly explained.
What problems still remain, and how can AI solve them? I spend tonight pondering these questions.