Diary - LLM에서 효율적인 강화학습이란 무엇일까 2 (feat. Qwen-3.5와 GLM-5)
26 Feb 2026LLM에서 효율적인 강화학습이란 무엇일까라는 글을 쓰고있는데, Qwen-3.5와 GLM-5가 출시되었다. 이걸 보니까 또 많은 생각이…ㅋㅋㅋ 아무튼 또 다시 효율적인 RL이라는 관점에서 두 모델의 주요 내용과 생각을 정리해 본다.
Async RL
GLM-5와 Qwen3.5 모두 이전 버전에 비해 Agent 성능을 강화하는데 집중했다 (시대의 흐름상 당연하게도). 따라서 Agent RL이 학습의 핵심 파이프라인 중 하나라고 볼 수 있는데, Agent task의 특성상 환경과 상호작용하는 시간이 길다. tool을 실행하고 결과를 기다리고, 그 과정에서 웹페이지를 로딩하고 API 응답을 받는다.
이건 진짜 순수하게 기다리는 시간이다. 가장 중요한 Training에 사용되는 GPU가 너무 놀아버리게 될 뿐만 아니라 Inference에도 GPU를 안쓰는거니까. 따라서 Agent RL은 다른 Reasoning RL등과 다르게, 반드시 Asynchronous RL 파이프라인을 적용해야 한다.
Asynchronous RL이란, Rollout과 Training 을 완전히 분리하는 방식이다. 원래 On-policy RL알고리즘인 PPO 계열 (GRPO 등)을 엄밀하게 쓰려면 rollout -> training -> rollout 이런식으로 번갈아가면서 RL을 수행해야 한다. Rollout은 vllm 엔진을 쓰고 training은 megatron 엔진을 쓰니까 parameter를 올렸다 내렸다 하기도 하고, inference bubble 이 생기기도 한다. 이런 병목을 해결하기 위해서 아예 rollout과 training 에 사용되는 GPU를 분리하는 방식이 async RL 이다.
아래는 Sync RL과 Async RL을 보여주는 그림 (출처: verl)

Off-Policy의 딜레마
Async RL을 하면 완벽한 on-policy가 될 수 없다. Rollout을 생성한 시점의 policy와 학습하는 시점의 policy가 달라지기 때문이다. 실제로 이 차이가 학습 불안정성이나 성능 악화와 이어지게 된다. 그래서 약간의 async를 하더라도 주기적으로 계속 동기화 시켜주는 과정을 통해 이 gap을 최소화 하게 된다.
Qwen3.5는 “Staleness gradient bounding”이라는 기법을 사용했다고 한다 (Technical paper가 아직 공개되지 않아서 정확히는 모르겠지만 공개된 파이프라인 그림을 보고 대충 추정한다). GLM-5는 IcePop 알고리즘을 사용했다. 뭐가 되었든 두 모델에서 Off-policy 딜레마를 해결한 방법의 핵심은 같다.
On-policy에서 너무 멀어진 sample은 과감히 버린다.
IcePop을 알아보자면 training policy와 inference policy의 확률 비율이 [0.5, 2.0] 범위를 벗어나면 해당 sample의 gradient 기여를 0으로 만든다. 매우 단순하지만 아주 효과적인 방법론이라고 생각한다.
GPU Utilization에 대한 집념
두 모델 모두 Rollout/Training/Environment-interaction사이의 load balancing에 대해 언급하고 있다. GPU utilization을 극한까지 끌어올리기 위한 노력들. 개인적인 경험으로는 RL은 sample 수로만 보면 엄청나게 비싼데, 성능 개선 폭은 그렇게 비싸지는 않다. 초당 학습하는 sample 수는 SFT랑 비교하면 1/100도 안되는데도, post-training 후반부에서는 비슷한 성능 향상폭을 보여주기 때문이다. GPU utilization 1%를 올려서 출시를 AGI의 도래를 1년 앞당길수도 있다.
특히 이번 Qwen3.5에서 공개한 파이프라인 그림을 보고 너무 예쁘다고 생각하면서도, 저 파이프라인을 실제로 구현하기 위해 엄청나게 많은 LLM 엔지니어와 인프라 엔지니어들이 갈려나갔을거라고 확신했다.
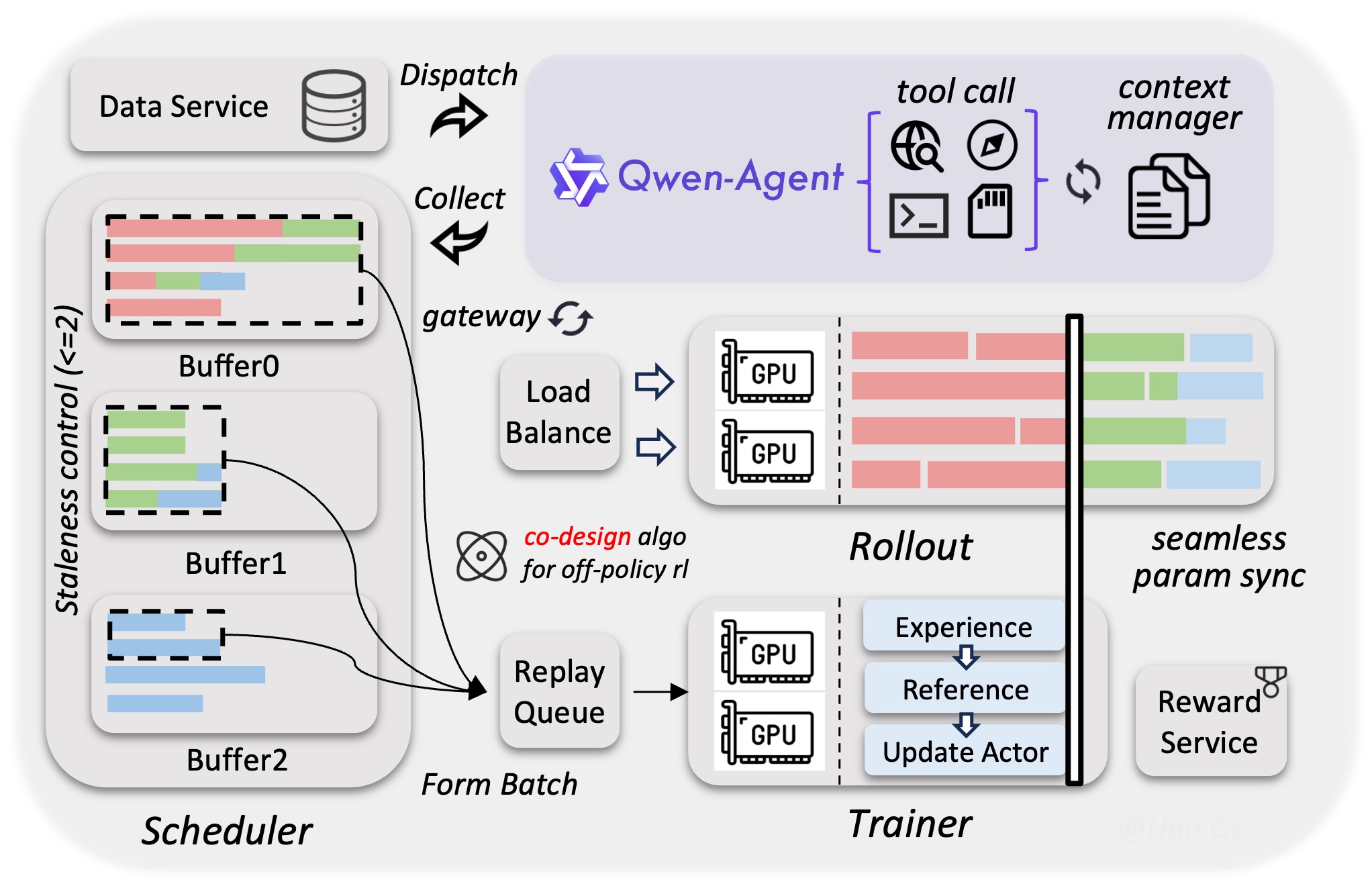
아주 단순하게 적어두고 그려두었지만, 인프라 하드웨어는 느려질 때도 있고 고장날 때도 있다. 또 Training과 Inference 간의 param sync를 맞출 때 통신 병목도 있고, 타이밍이에 따라서 GPU bubble도 생긴다. MoE router 이후 token 재분배에서도 병목이 발생한다. 이런 점들이 다각도로 고려되어야 한다. 단순해보이는 Async RL 프레임워크이지만 진짜 엄청난 소프트웨어 역량의 결집이 있다. 대단하다고 느낀다.
실용적이고 강력한 테크닉들
사실 논문과 블로그를 살펴보니, Async RL 파이프라인 이외에도 굉장히 실용적이면서 강력한 테크닉들이 눈에 띈다.
Qwen3.5의 동적 precision 관리: FP8으로 학습하다가 민감한 layer가 감지되면 자동으로 BF16으로 올린다. Runtime monitoring으로 안정성과 효율성을 동시에 잡는다. (오…학습 도중에 이런게 된다고? 멈추고 바꾸는게 아니고?)
GLM-5의 Error Masking: Multi-turn 데이터에서 에러가 발생한 부분을 버리지 않는다. 대신 loss mask를 적용해서 에러 자체는 학습하지 않되, 에러를 수정하는 행동은 학습하게 만든다. SFT 단계의 적용된건데, 발상이 좋다. SFT는 사실 무조건 품질을 올리는게 중요해서 error가 있는 데이터를 빼는게 정설이다. 그런데 GLM-5는 error-masking을 통해서 모델이 잘못된 답변을 내더라도 다음턴에서 다시 벗어나기 위한 multi-turn 성능을 올려줬다고 한다.
Inference 속도 개선: 결국 병목은 rollout에서 발생한다. MTP (Multi-Token Prediction) 을 이용한 speculative decoding, DP-aware KV-cache 등을 통해서 Inference 속도를 최대한 올려줬다고 한다. 결국 API Inference 담당하던 엔지니어들까지 학습단에 달라붙어서 Async RL 파이프라인 안에서 전부 잘 작동하게 만든 것.
야밤에 드는 생각들 정리
Multimodal RL
2026년 LLM technical paper 들에서 집중될 내용은 단언컨데 multi-modal RL일 것이다. 이미지 생성, 음성 입출력에 대한 environment interaction은 텍스트보다 훨씬 비쌀 것이다. 이미지 한 장 생성하는 데 걸리는 시간, 음성을 처리하는 데 걸리는 시간. 기본적으로 텍스트 토크나이징보다 더 많은 시간을 요구된다. 이 병목을 줄여나가는 데 역량이 집중될 것이다. 또 Modality를 확장하는건 여러 training stage를 거쳐야 하는데, 비싸고 불안정한 RL을 통해 여러 modality의 성능을 함께 올릴 수 있는가에 대해서도 계속 연구가 필요하다. (사실 Qwen3.5는 image-text-to-text 모델이라 이런 부분도 이미 일정부분 고려가 되었다)
그래도 공개해줘서 고맙다
어떻게 학습했는지 이정도만 공개해줘도 너무 고맙다. Anthropic, Google, OpenAI 는 대체 뭘 어떻게 하고 있는지 감도 안온다. 아마 비슷한 과정을 3개월 정도 앞서서 하고 있는 거겠지. 위에서 말했던 Async RL을 Claude Opus 4.6으로 자동화시켜서 돌리고 있는걸지도 모른다.
텍스트는 이정도가 한계일까?
사실 좀 오랜만에 Technical report를 읽었는데, saturation이 눈에 보인다. Text 기반 벤치마크에서 모델 간 격차가 솔직히 별로 없는 것 같고, 벤치마크도 좀 억지스러운가 싶기도 하다. 또 유저로서 실제로 체감하는 성능 차이도 크지 않다. 솔직히 말해서 요새 나오는 모델들은 이름 다 가려놓고 같은 opencode에 붙인다음에 구별해보라고 하면 못할 것 같다. 내가 풀고 있는 문제들이 사실 크게 어렵지 않은 것일지도 모르지만 갑자기 모델을 바꾸더라도 불만은 없을 것 같다.
그럼에도 불구하고
그러나 여전히 현재의 SOTA 모델로 단숨에 해결할 수 없는 문제들이 세상에는 많다. 특히나 말로 표현하기 어려운 것들. 사람이 굉장히 많은 것을 학습하고 지식과 능력으로 구축했지만, 그것은 사람 안에 intrinsic하게 남아있다. 가치관, 성격, 협동, 메타인지, 장기기억, 기억의 소멸, 연상작용. 우리는 이것들을 동원해서 눈앞에 있는 다양한 문제를 풀어나간다. 아직까지는 명시적으로 설명할 수 없는 방식들을 동원해서.
아직 어떤 문제들이 남아 있고, AI가 이것을 어떻게 풀어낼 수 있을까. 이런 고민을 하며 오늘 밤을 지낸다.